Cloud Confusing
Explaining hosting, AWS, Wordpress, static sites, and all manner of cloud solutions.
An Abbreviated Guide to S3 Redirection Rules
If you are looking for an explainer on S3 redirection rules, you are going to have a tough time finding a good one. While information on redirection rules is available from all over, no one source (including Amazon) is even close to complete. Then outcomes don’t always match exceptions. Welcome to cloud confusion!
This guide should help with some of your S3 redirection questions. At the very least it’ll cover the major concepts and get you on your way to having a static web site with properly working 301s, 302s and other such options.
What are S3 Redirection Rules?
By means of example: Let’s say you have a blog that you no longer use but you don’t want to shut it down. Instead, you want to turn it into a static website, hosted on AWS S3, that is nearly free to run and will never require an update, security patch, or maintanence. Easy enough with the aforementioned S3 hosting guide, right? You can even rebuild the directory structure in S3 so that some old articles will still work (like MySite.com/2017/12/article.html) using S3 folders. In fact, here is a site I build to demo this. It’s about rollerball pens.
Rebuilding the directory is great for a few top articles, but what if you want to redirect all your old images to the home page or 301 all the articles from 2014 (MySite.com/2014/*)? You need a some kind of routing rule… possibly a conditional Redirection Rule.
Time for some good news/bad news. The good? S3 is very good a redirecting URLs. The bad? S3 is so good that there are multiple overlapping options and you have to figure them out and keep track of what you have in place. The official AWS guide is here, if you want a reference point.
S3 Static Website Hosting Redirect Requests
To start with redirect requests, go to S3, find your site’s bucket, click into it, and navigate to the Permissions section.
Here you will find a set of options for Static Website Hosting. It looks like this:
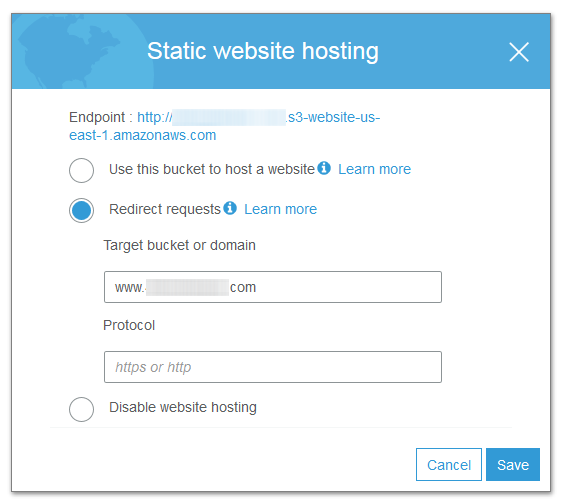
Here you can choose to redirect an entire bucket to another URL — this is the most simple form of S3 redirection. It’s normally used to redirect an empty bucket, say www.mySite.com, to the functioning one at mySite.com. This way you can have a site with a working www subdomain without actually maintaining that bucket.
S3 Static Website Hosting Routing Rules
If you instead opt to “Use this bucket to host a website” you can then use the S3 redirection rules. These are powerful XML-like instructions that can handle all sorts of URLs and URL sets along with specific responses (404, 301, etc.).
Note: These only work if you use the correct S3 endpoints! I can’t stress how important this is. No advanced S3 functions will work without, but your site will work fine otherwise so you’ll be in for a world of troubleshooting pain if you don’t do this correctly from the start.
These rules look like this:
<RoutingRules>
<RoutingRule>
<Condition>
<KeyPrefixEquals/>
<HttpErrorCodeReturnedEquals>404</HttpErrorCodeReturnedEquals> </Condition>
<Redirect>
<HostName>www.MySite.com</HostName>
<ReplaceKeyWith/>
</Redirect>
</RoutingRule>
</RoutingRules>
These redirect rules are, too put it nicely, awful to work with. They are poorly documented and difficult to write. The syntax, to my eye, looks strange as well. But the good news is that they work and they are easy enough to diagnose when they go wrong — just keep pounding those URLs and looking for the desired response!
Amazon has a few Routing Rule examples as well as the elements (that is, the available tools) posted, but I’ve found the docs to be very limited here.
Also note that, as with many parts of S3, there are some annoying quirks. For example if you wanted to redirect missing content to another part of the site you’d consider using a 404 code, but S3 won’t do a 404 unless you have permission to view the bucket (ie: s3:ListBucket permission on the bucket), so you need a 403 which then redirects to your desired destination.
Another sample redirection policy might look like this:
<RoutingRules>
<RoutingRule>
<Condition>
<HttpErrorCodeReturnedEquals>404</HttpErrorCodeReturnedEquals>
</Condition>
<Redirect>
<HostName>yourdomainname.com</HostName>
<ReplaceKeyPrefixWith>#!/</ReplaceKeyPrefixWith>
</Redirect>
</RoutingRule>
</RoutingRules>
if you wanted to add a hash-bang (#!) to your URLs where they might have been bookmarked without one.
S3 Bucket Policy
Technically you can handle URL redirects using S3 Bucket Policies as well, but that can get truly painful and more complex than we’ll need for now. The important thing to know is that S3 Bucket Policies normally handle access to a site, but they can also do things like x-amz-website-redirect-location which can redirect request as well.
In case you want to use this, make sure to try out Amazon’s Bucket Policy Generator, which actually works pretty well (though isn’t a good fit for AWS beginners).
S3 File-level Metadata
If you want to get specific with your redirection and you don’t want to use the Routing Rules, you can set the metadata on an individual files to redirect. This is manual, hard to track, hard to scale, and somewhat obscure, but it’s doable.
This method is manual but very simple and intuitive. You have a file and that file has metadata telling the browser how to work with it.
Just navigate S3, then to your bucket, then to the file in question. At the file go to Properties, and then find Metadata. Now select “Add Website Redirect Location” and then put in the destination — either something like /page1.html or another site altogether! This will create a 301 that redirects from that file (it can be a .html, whatever) to your desired location. This will create a proper 301 so it’s an SEO-friendly approach.
Here is a working example of a metadata redirect: https://rollerpen.org/index2.php. You can test to see that it generates a 301 “Moved Permanently” response code, as intended.
Sal September 10th, 2019
Posted In: AWS
Tags: Hosting, Redirection Rules, Routing, S3